15 KiB
| layout | title | date | categories |
|---|---|---|---|
| post | Home Lab Infrastructure Snapshot August 2023 | 2023-08-27 22:23:00 Europe/Amsterdam | infrastructure homelab |
I have been meaning to write about the current state of my home lab infrastructure for a while now. Now that the most important parts are quite stable, I think the opportunity is ripe. I expect this post to get quite long, so I might have to leave out some details along the way.
This post will be a starting point for future infrastructure snapshots which I can hopefully put out periodically. That is, if there is enough worth talking about.
Keep an eye out for the icon, which links to the source code and configuration of anything mentioned. Oh yeah, did I mention everything I do is open source?
Networking and Infrastructure Overview
Hardware and Operating Systems
Let's start with the basics: what kind of hardware do I use for my home lab? The most important servers are my three Gigabyte Brix GB-BLCE-4105. Two of them have 16 GB of memory, and one 8 GB. I named these servers as follows:
- Atlas: because this server was going to "lift" a lot of virtual machines.
- Lewis: we started out with a "Max" server named after the Formula 1 driver Max Verstappen, but it kind of became an unmanagable behemoth without infrastructure-as-code. Our second server we subsequently named Lewis after his colleague Lewis Hamilton. Note: people around me vetoed these names and I am no F1 fan!
- Jefke: it's a funny Belgian name. That's all.
Here is a picture of them sitting in their cosy closet:

If you look look to the left, you will also see a Raspberry pi 4B. I use this Pi to do some rudimentary monitoring whether servers and services are running. More on this in the relevant section below. The Pi is called Iris because it's a messenger for the other servers.
I used to run Ubuntu on these systems, but I have since migrated away to Debian. The main reasons were Canonical putting advertisements in my terminal and pushing Snap which has a proprietry backend. Two of my servers run the newly released Debian Bookworm, while one still runs Debian Bullseye.
Networking
For networking, I wanted hypervisors and virtual machines separated by VLANs for security reasons. The following picture shows a simplified view of the VLANs present in my home lab:
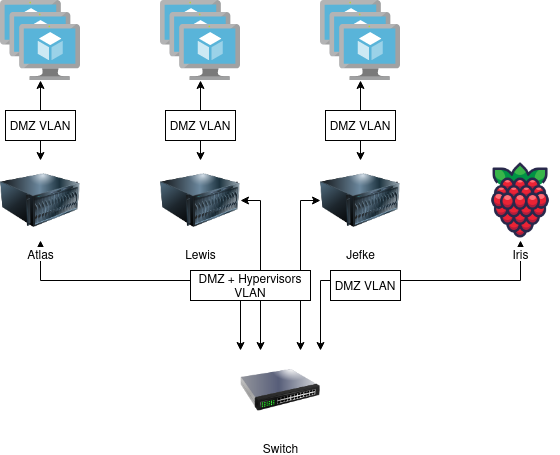
All virtual machines are connected to a virtual bridge which tags network traffic with the DMZ VLAN. The hypervisors VLAN is used for traffic to and from the hypervisors. Devices from the hypervisors VLAN are allowed to connect to devices in the DMZ, but not vice versa. The hypervisors are connected to a switch using a trunk link, allows both DMZ and hypervisors traffic.
I realised the above design using ifupdown.
Below is the configuration for each hypervisor, which creates a new enp3s0.30 interface with all DMZ traffic from the enp3s0 interface .
auto enp3s0.30
iface enp3s0.30 inet manual
iface enp3s0.30 inet6 auto
accept_ra 0
dhcp 0
request_prefix 0
privext 0
pre-up sysctl -w net/ipv6/conf/enp3s0.30/disable_ipv6=1
This configuration seems more complex than it actually is.
Most of it is to make sure the interface is not assigned an IPv4/6 address on the hypervisor host.
The magic .30 at the end of the interface name makes this interface tagged with VLAN ID 30 (DMZ for me).
Now that we have an interface tagged for the DMZ VLAN, we can create a bridge where future virtual machines can connect to:
auto dmzbr
iface dmzbr inet manual
bridge_ports enp3s0.30
bridge_stp off
iface dmzbr inet6 auto
accept_ra 0
dhcp 0
request_prefix 0
privext 0
pre-up sysctl -w net/ipv6/conf/dmzbr/disable_ipv6=1
Just like the previous config, this is quite bloated because I don't want the interface to be assigned an IP address on the host.
Most importantly, the bridge_ports enp3s0.30 line here makes this interface a virtual bridge for the enp3s0.30 interface.
And voilà, we now have a virtual bridge on each machine, where only DMZ traffic will flow. Here I verify whether this configuration works:
Show
We can see that the two virtual interfaces are created, and are only assigned a MAC address and not a IP address:
root@atlas:~# ip a show enp3s0.30
4: enp3s0.30@enp3s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master dmzbr state UP group default qlen 1000
link/ether d8:5e:d3:4c:70:38 brd ff:ff:ff:ff:ff:ff
5: dmzbr: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 4e:f7:1f:0f:ad:17 brd ff:ff:ff:ff:ff:ff
Pinging a VM from a hypervisor works:
root@atlas:~# ping -c1 maestro.dmz
PING maestro.dmz (192.168.30.8) 56(84) bytes of data.
64 bytes from 192.168.30.8 (192.168.30.8): icmp_seq=1 ttl=63 time=0.457 ms
Pinging a hypervisor from a VM does not work:
root@maestro:~# ping -c1 atlas.hyp
PING atlas.hyp (192.168.40.2) 56(84) bytes of data.
--- atlas.hyp ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
DNS and DHCP
Now that we have a working DMZ network, let's build on it to get DNS and DHCP working. This will enable new virtual machines to obtain a static or dynamic IP address and register their host in DNS. This has actually been incredibly annoying due to our friend Network address translation (NAT).
NAT recap
Network address translation (NAT) is a function of a router which allows multiple hosts to share a single IP address. This is needed for IPv4, because IPv4 addresses are scarce and usually one household is only assigned a single IPv4 address. This is one of the problems IPv6 attempts to solve (mainly by having so many IP addresses that they should never run out). To solve the problem for IPv4, each host in a network is assigned a private IPv4 address, which can be reused for every network.
Then, the router must perform address translation. It does this by keeping track of ports opened by hosts in its private network. If a packet from the internet arrives at the router for such a port, it forwards this packet to the correct host.
I would like to host my own DNS on a virtual machine (called hermes, more on VMs later) in the DMZ network. This basically gives two problems:
- The upstream DNS server will refer to the public internet-accessible IP address of our DNS server. This IP-address has no meaning inside the private network due to NAT and the router will reject the packet.
- Our DNS resolves hosts to their public internet-accessible IP address. This is similar to the previous problem as the public IP address has no meaning.
The first problem can be remediated by overriding the location of the DNS server for hosts inside the DMZ network. This can be achieved on my router, which uses Unbound as its recursive DNS server:
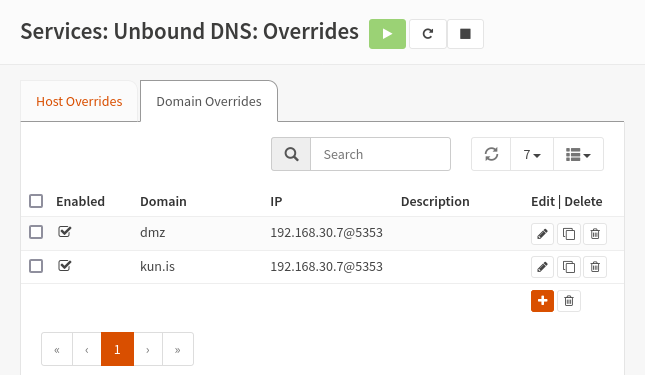
Any DNS requests to Unbound to domains in either dmz or kun.is will now be forwarded 192.168.30.7 (port 5353).
This is the virtual machine hosting my DNS.
The second problem can be solved at the DNS server. We need to do some magic overriding, which dnsmasq is perfect for :
alias=84.245.14.149,192.168.30.8
server=/kun.is/192.168.30.7
This always overrides the public IPv4 address to the private one.
It also overrides the DNS server for kun.is to 192.168.30.7.
Finally, behind the dnsmasq server, I run Powerdns as authoritative DNS server . I like this DNS server because I can manage it with Terraform .
Here is a small diagram showing my setup (my networking teacher would probably kill me for this):
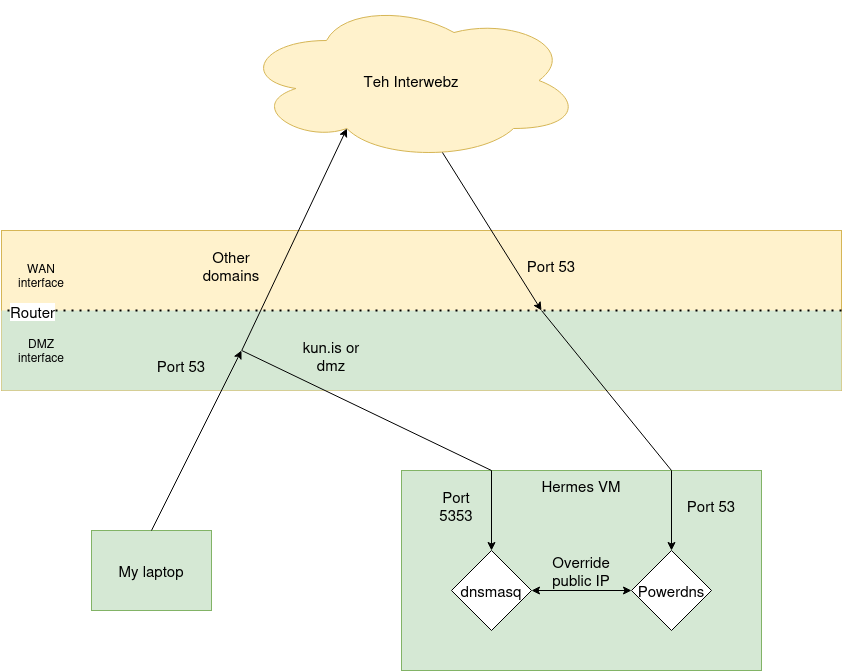
Virtualization
https://github.com/containrrr/shepherd Now that we have laid out the basic networking, let's talk virtualization. Each of my servers are configured to run KVM virtual machines, orchestrated using Libvirt. Configuration of the physical hypervisor servers, including KVM/Libvirt is done using Ansible. The VMs are spun up using Terraform and the dmacvicar/libvirt Terraform provider.
This all isn't too exciting, except that I created a Terraform module that abstracts the Terraform Libvirt provider for my specific scenario :
module "maestro" {
source = "git::https://git.kun.is/home/tf-modules.git//debian"
name = "maestro"
domain_name = "tf-maestro"
memory = 10240
mac = "CA:FE:C0:FF:EE:08"
}
This automatically creates a Debian virtual machines with the properties specified. It also sets up certificate-based SSH authentication which I talked about [before]({% post_url homebrew-ssh-ca/2023-05-23-homebrew-ssh-ca %}).
Clustering
With virtualization explained, let's move up one level further. Each of my three physical servers hosts a virtual machine running Docker, which together form a Docker Swarm. I use Traefik as a reverse proxy which routes requests to the correct container.
All data is hosted on a single machine and made available to containers using NFS. This might not be very secure (as NFS is not encrypted and no proper authentication), it is quite fast.
As of today, I host the following services on my Docker Swarm :
- Forgejo as Git server
- FreshRSS as RSS aggregator
- Hedgedoc as Markdown note-taking
- Inbucket for disposable email
- Cyberchef for the lulz
- Kitchenowl for grocery lists
- Mastodon for microblogging
- A monitoring stack (read more below)
- Nextcloud for cloud storage
- Pihole to block advertisements
- Radicale for calendar and contacts sync
- Seafile for cloud storage and sync
- Shephard for automatic container updates
- Nginx hosting static content (like this page!)
- Docker Swarm dashboard
- Syncthing for file sync
CI / CD
For CI / CD, I run Concourse CI in a separate VM. This is needed, because Concourse heavily uses containers to create reproducible builds.
Although I should probably use it for more, I currently use my Concourse for three pipelines:
- A pipeline to build this static website and create a container image of it. The image is then uploaded to the image registry of my Forgejo instance. I love it when I can use stuff I previously built :) The pipeline finally deploys this new image to the Docker Swarm .
- A pipeline to create a Concourse resource that sends Apprise alerts (Concourse-ception?)
- A pipeline to build a custom Fluentd image with plugins installed
Backups
To create backups, I use Borg. As I keep all data on one machine, this backup process is quite simple. In fact, all this data is stored in a single Libvirt volume. To configure Borg with a simple declarative script, I use Borgmatic.
In order to back up the data inside the Libvirt volume, I create a snapshot to a file. Then I can mount this snapshot in my file system. The files can then be backed up while the system is still running. It is also possible to simply back up the Libvirt image, but this takes more time and storage .
Monitoring and Alerting
The last topic I would like to talk about is monitoring and alerting. This is something I'm still actively improving and only just set up properly.
Alerting
For alerting, I wanted something that runs entirely on my own infrastructure. I settled for Apprise + Ntfy.
Apprise is a server that is able to send notifications to dozens of services. For application developers, it is thus only necessary to implement the Apprise API to gain access to all these services. The Apprise API itself is also very simple. By using Apprise, I can also easily switch to another notification service later. Ntfy is free software made for mobile push notifications.
I use this alerting system in quite a lot of places in my infrastructure, for example when creating backups.
Uptime Monitoring
The first monitoring setup I created, was using Uptime Kuma. Uptime Kuma periodically pings a service to see whether it is still running. You can do a literal ping, test HTTP response codes, check database connectivity and much more. I use it to check whether my services and VMs are online. And the best part is, Uptime Kuma supports Apprise so I get push notifications on my phone whenever something goes down!
Metrics and Log Monitoring
A new monitoring system I am still in the process of deploying is focused on metrics and logs. I plan on creating a separate blog post about this, so keep an eye out on that (for example using RSS :)). Safe to say, it is no basic ELK stack!
Conclusion
That's it for now! Hopefully I inspired someone to build something... or how not to :)